v0.12: Replay, custom scheduling

Version v0.12 of FlexMeasures adds a cool re-play feature and support for adding custom scheduling algorithms!
Actually, this release is a big one with many small improvements, e.g. the CLI for data ingestions have taken a big leap.
See changelog or read on below to read what we added.
Replay
FlexMeasures shines in keeping track what was known at what time. In both simulations and real time operation, we found that our partners want to see how the data situation progressed over time.
That's why we decided to add a replay-button to asset dashboards. It travels through time for you:
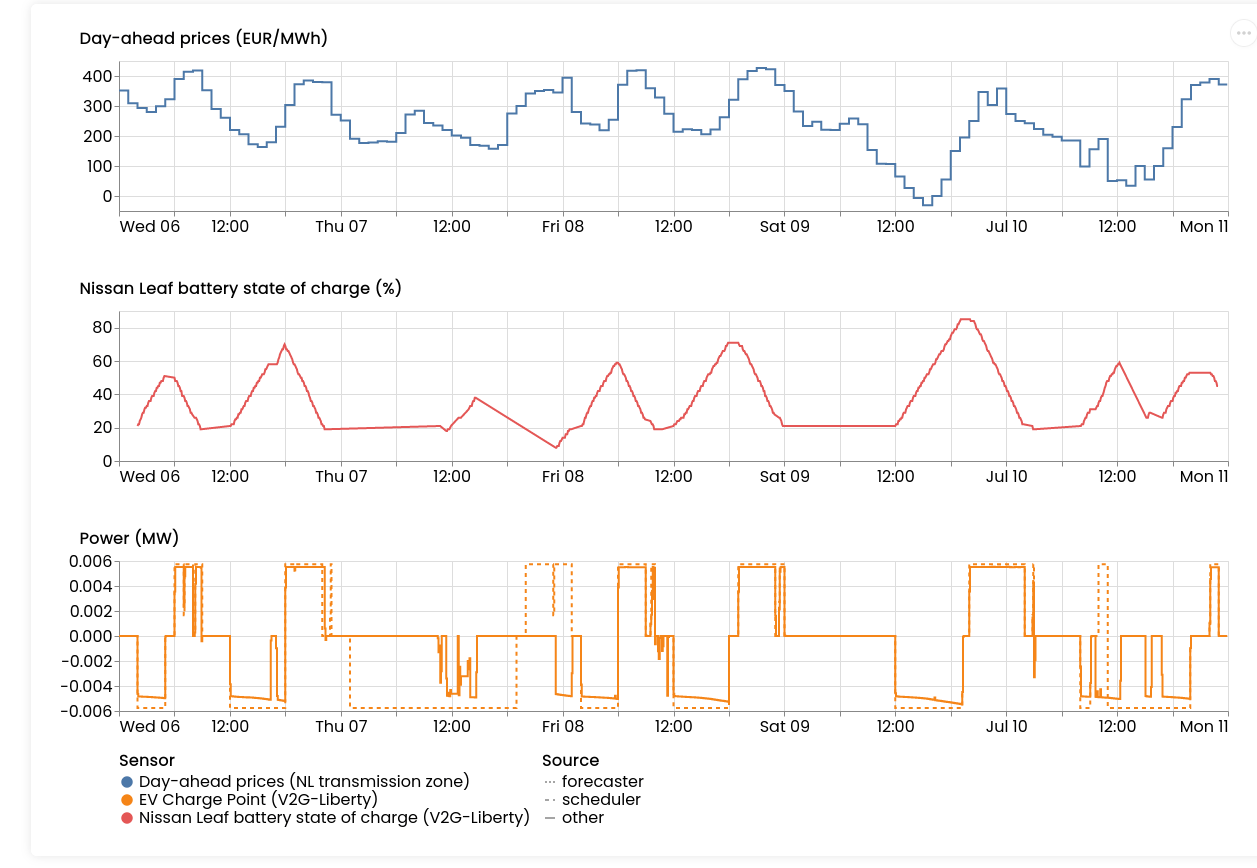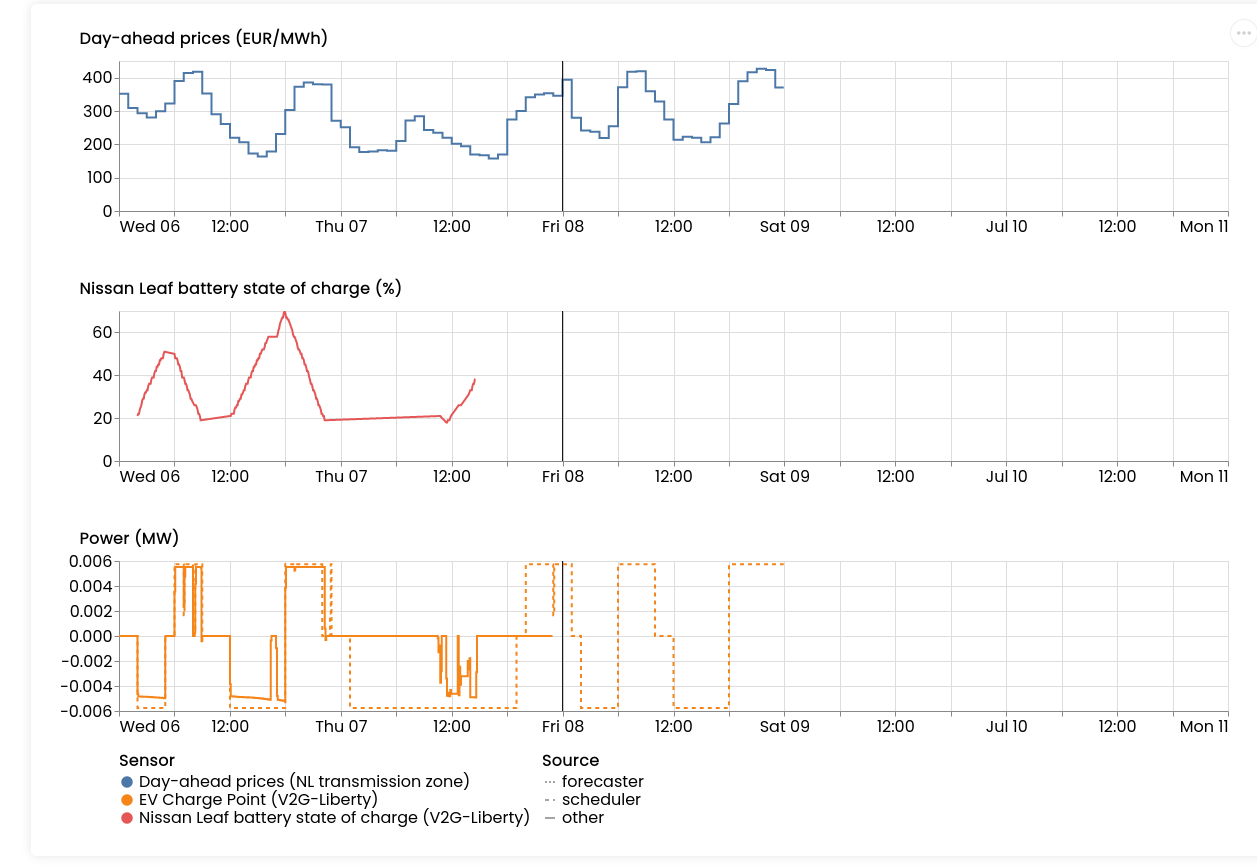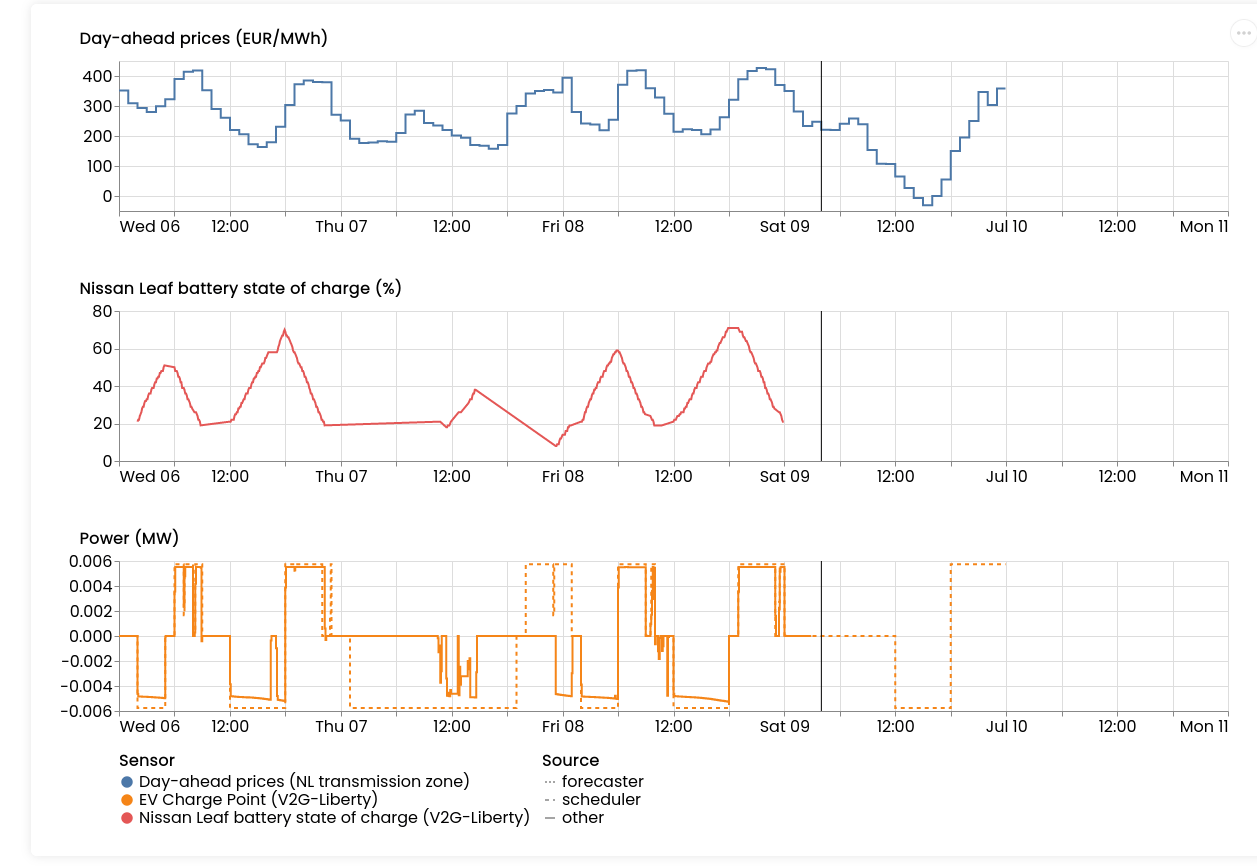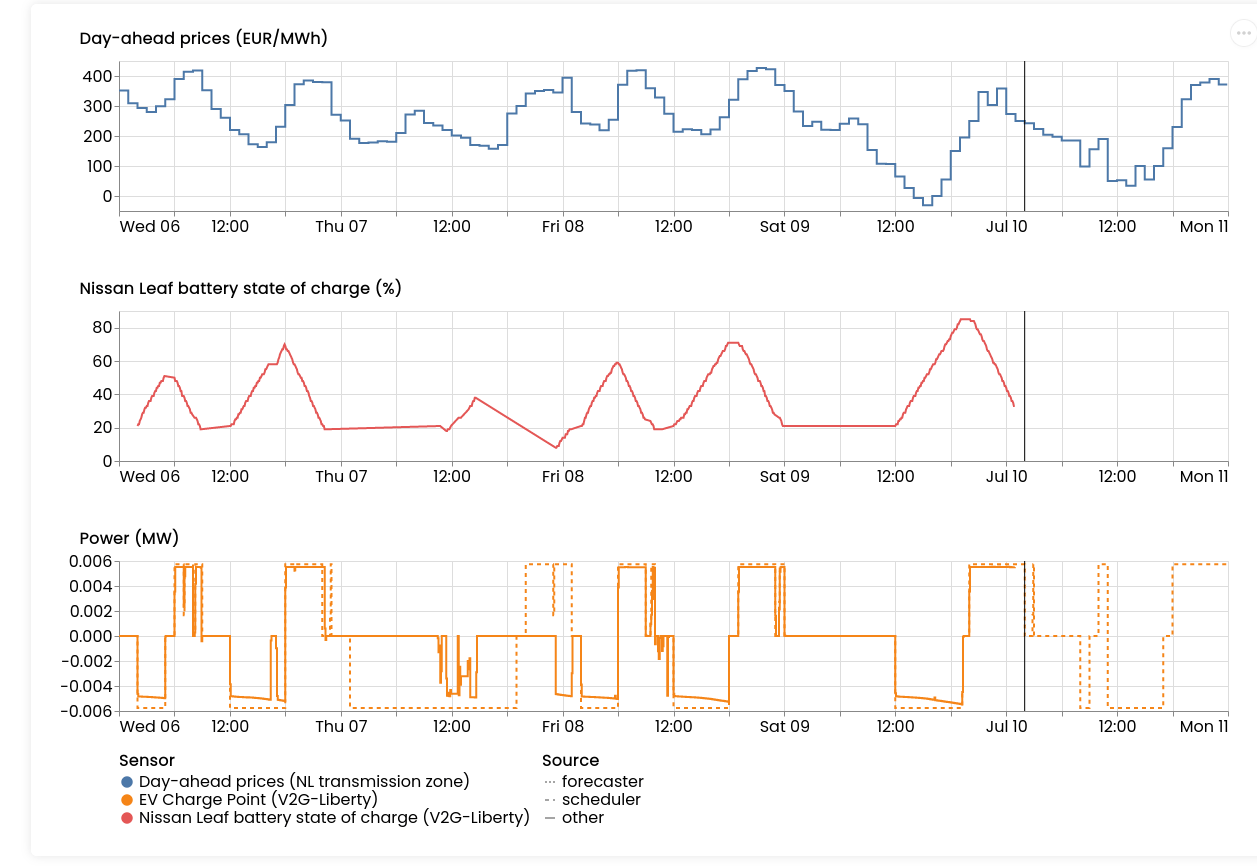
Where is this useful? We've seen this work very well in demos, and to explain why certain schedules were executed half-way, but then the rest got re-written. This happens because when new data arrives (e.g. prices change, an EV re-connects to the charger, etc.), FlexMeasures needs to re-compute the schedule.
This has been in the works for a long time, and now finally released. This work was done in Pull Request 463.
Custom scheduling
To schedule flexible assets is the main premise of FlexMeasures. More concretely, the mission of FlexMeasures is to drastically cut down the development time on any flexibility solution, no matter if an in-built scheduler already is applicable.
Together with the plugin support released in v0.7, this release comes with support for people writing their own schedulers.
This is relevant to researchers and startups who are innovating in the realm of algorithms, but still would like to save development time (and use FlexMeasures as a framework and web application in which to embed their logic).
We will use this internally as well, as it makes any new project easier. Usually, we don't work on new schedulers in the open ― we prefer to iterate in a plugin first. If the result is great, then it'll enter FlexMeasures core.
Up until now, schedulers were an internal feature, accessible by an API, but focused on storage flexibility for the main part (we worked on shiftable flexibility in other projects). Opening a core feature up for other use cases is really helpful to arrive at a better design. We've completely refactored how schedulers are implemented and how to give them the necessary information (the flex-model and the flex-context), and we're very excited how this will empower our own work and that of FlexMeasures users.
The plugin developer tutorial and this part of the API notation docs tell you more.
This work was done in Pull Requests 505, 511, 537, 568 and 566.
Ingesting data on the CLI
Almost every project involves getting some historical data read in (e.g. from CSV or Excel files), be it because one uses FlexMeasures to run simulations, or to have a base data set for machine learning purposes (e.g. a forecasting algorithm). This is tough and iterative engineering work.
FlexMeasures has CLI support for this (flexmeasures add beliefs). We tackled several issues to make this work even more developer-friendly:
- drop duplicate records with warning
- allow configuring which column contains explicit recording times for each data point (use case: import forecasts)
- localize timezone naive data
- support reading in datetime and timedelta values
- remove rows with NaN values
- filter by values in specific columns
We also improved its counterpart, flexmeasures show beliefs. We now support:
- showing beliefs data in a custom resolution and/or timezone
- saving the shown beliefs data to a CSV file
- handle showing (and saving) instantaneous sensor data and non-instantaneous sensor data together
This work was done in Pull Requests 501, 521, 519 and 542.